介绍
本文是关于 Person Re-ID 的一个简要介绍, 主要参考了论文 [1].
行人重识别的是要解决在多摄像头 (一般来说是非重叠的) 场景下, 对摄像头中的行人进行查找/识别, 通常行人在一个摄像头出现而后消失, 一段时间后出现在另一个摄像头.
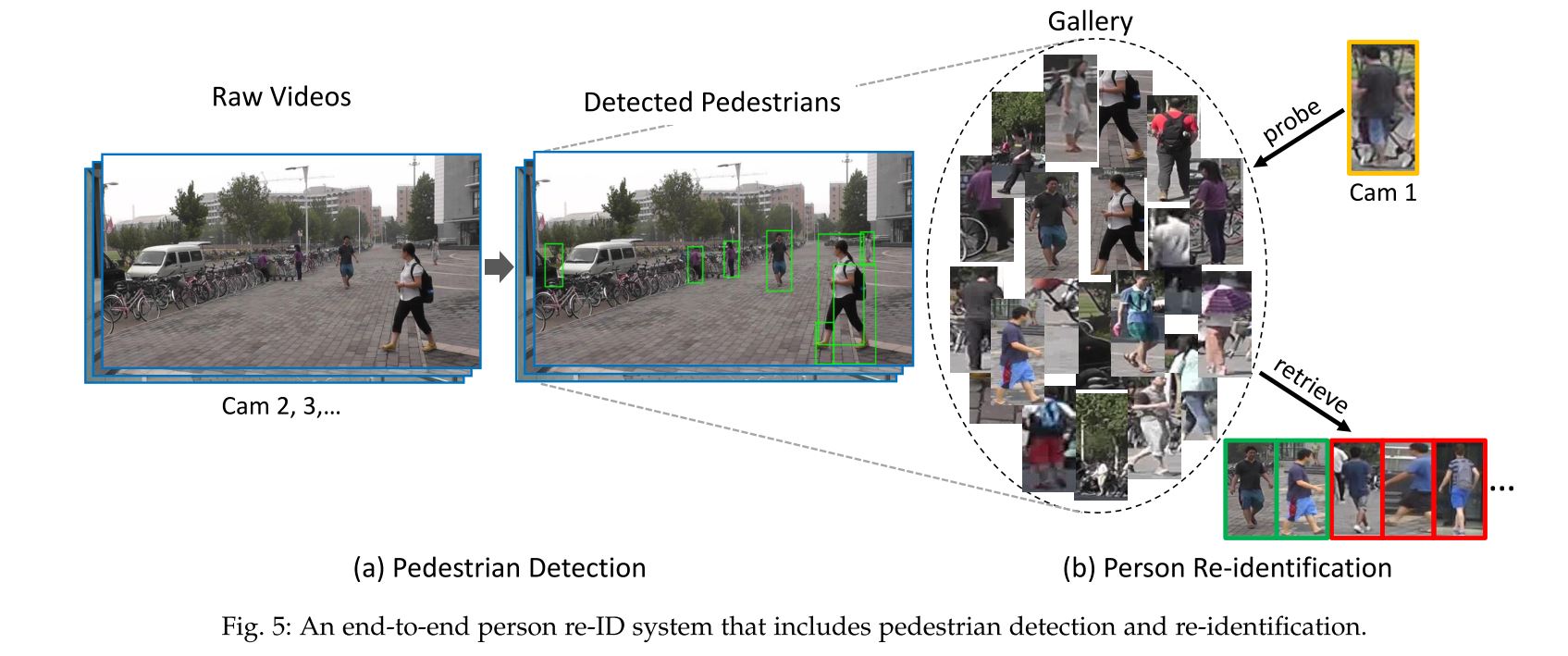
行人重识别一般包括行人检测 (person detection), 行人跟踪 (person tracking) 和行人查询 (Person retrieval) 几个流程. 但是鉴于前两者已经作为单独的课题被研究地较为成熟了, 我们主要讨论的其实是第三个部分.
目标
由于监控摄像头的覆盖范围有限, 同时考虑到经济成本, 总有摄像头盲区, 因此当一个人从一个摄像头转移到另一个摄像头时能对人进行识别和跟踪是非常重要的. 这个问题就是所谓的行人重识别. 可以更加正式地表示为, 给定一个 gallery set \(G\) 包含 \(N\) 张不同的图片 \( \{ g_i \}_{i=1}^N \), 每张图片对应 \( N \) 个 identity 中的一个. 我们希望针对一个给定的 probe (query) image \( q \) 能通过下式来确定其属于哪一个 identity:
\[i*=\arg \max_{i \in 1,2,\ldots,N} \mathrm{sim}(q,g_i)\]其中 \( \mathrm{sim}(q,g_i) \) 表示图片 \( q \) 和 \( g_i \) 之间的相似度. 实际上这是一个简化的 Person Re-ID 问题, 属于 close-world 的, 近似于分类问题. 实际上我们可能会有更多的要求, 例如过滤掉 gallery set 中的无关对象 (imposters), 或是判断某张图像是否属于特定的 group 等.
挑战
这一领域的挑战在于数据之间的差异性非常巨大, 即同类 (同一个人) 之间的差异相对比较大而类间 (不同人间) 差异不太大, 具有区分性的特征不够明显. 具体来说是由于
- 不同摄像头的角度, 背景, 光照等条件存在很大差异, 同一个人在不同摄像头下可能存在很大的差异
- 行人的动作, 姿态可能发生改变
- 摄像头分辨率相对较低, 不可能通过检测人脸来完成识别
- 标记数据量小, 这在一定程度上限制了深度学习在该领域的使用
如何解决上述数据差异大的问题
关于上面提到的挑战, 目前学术界主要的应对方法有
- 提取具有辨识度和鲁棒性的数据特征
提取所用的大部分特征都是外貌特征 (apperance features), 例如颜色, 梯度, 边沿等. 其他一些基于特征提取的模型还包括 color histogram, graph model, spatial co-occurrence representation model, principal axis, rectangle region histogram, part-based models 等 [2].
比如论文 Learning Mid-level Filters for Person Re-identification 中使用一致聚类 (coherent cluster) 的方法来学习中层滤波器 (mid-level filters), 中层滤波器能提取人体不同部位尽可能具有辨识度同时又具有泛化能力的块 (patch). 所谓中层是指其提取的是区别于普遍块 (general patch) 和稀有块 (rare patch) 的有效块 (effective patch). 在普遍性和辨识度之间保持一个平衡是非常重要的, 太过于通用的块不能很好地区分不同的人, 然而如果只盯着行人的部分显著但不通用的特征又会陷入过拟合, 比如说假如有一个人穿了一件非常个性的衣服, 如果我们仅凭这个来辨别这个人, 那当他穿这件衣服的时候辨识度将会很高, 当不穿这件衣服时就很可能完全失去了辨别能力.
关于颜色, 边沿, 纹理等的特征属于低层次特征, 其语义性不太明显. 而还有一些特征是基于属性的, 比如说是否戴帽子等, 是一种中层次特征.
- 学习子空间映射模型, 在子空间中同类特征距离更小, 类间特征距离更大
即度量学习的问题. 事实上由于数据分布的特点, 很难提取一种具有很好的鲁棒性和区分性且同样的特征, 同一个人在不同的摄像头下将得到不同的特征. 由此我们可以从另一个角度来考虑, 在已经获得特征的情况下 (或许并不那么具有区分性), 如何设计一种距离度量方法来进行使得类内距离变小, 类间距离变大, 从而提高模型性能. 度量学习中广泛采用的 Mahalanobis 距离表示为
\[d(\mathbf{x}_i,\mathbf{x}_j)=(\mathbf{x}_i-\mathbf{x}_j)^T\mathbf{M}(\mathbf{x}_i-\mathbf{x}_j)\]其中 \(\mathbf{M}\) 为半正定矩阵, 表示为 \(\mathbf{M}\succcurlyeq0\).
度量学习本质上可以看成是一种子空间映射的方法, 先对原始特征进行子空间映射, 而后求映射后特征的欧氏距离. 比如说论文 Cross-view Asymmetric Metric Learning for Unsupervised Person Re-identification 中的方法使用一种非对称的距离.
\[d(\boldsymbol{x}_i^p, \boldsymbol{x}_j^q)=\|\boldsymbol{U}^{pT}\boldsymbol{x}_i^p-\boldsymbol{U}^{qT} \boldsymbol{x}_j^q\|_2\]来表示不同摄像头下特征的距离.
其他一些度量学习模型还包括 KISSME, LMNN (基于本地最近邻). 从子空间映射的角度还有 PCCA, LFDA 等模型.
Image based or Video based?
以上所述大多是 image-based, 即 probe set 和 gallery set 都是由图片组成, 甚至将图片中的每一个人都进行了分割. 这样虽然简化了问题, 但是另一方面却也丢失了很多可能对 re-id 有用的信息, 比如说行人周围的人, 因为在一些场景下 (比如说, 机场) 很多时候一群人总是在一起的, 我们就可以根据这一点来进行识别. 又或者我们可以根据行人的行为来进行识别. 要从 image-based 扩展到 video-based 只需要把上面第一条式子中的 \(g_i\) 和 \(q\) 分别改为一系列的 bounding box 即可.
基于视频的 Person Re-ID 通常更关注短时信息 (temporal information). 最早使用 video-based Person Re-ID 的是论文 Multiple-shot person re-identification by hpe signature 和 Person re-identification by symmetry-driven accumulation of local features, 使用策略类似于 image-based, 计算 bounding box feature 的最小欧氏距离来确定相似性. 之后的一些模型的策略还包括
- 使用协方差特征来训练集成判别模型
- 使用 SURF 局部特征来检测和描述视频序列中的感兴趣点
- 使用 spatial temporal graph 来寻找时空稳定区域 (spatial-temporal stable regions), 用以前景分割
- 使用多种几何结构来构建更为紧凑的空间描述符和颜色特征
- 使用条件随机场 (CRF) 来限制时空域
- 假设 probe feature 可以被 gallery set 中的同一类对象特征的线性组合来表示
- 使用多帧图片来进行身体对齐
- …
另外, 也可以利用行为/动作识别的方法, 从行为的角度来区分行人.
深度学习与 Person Re-ID
几年来深度学习大火, 必然会蔓延到 Person Re-ID 领域, 深度学习的优势在于可以自动提取有用的, 层次化的特征. 14 年, 有人利用 miamese networks 来对两张图像是否来自同一类进行判断. Miamese netowrks (孪生网络) 可以用来度量两张图片的相似度, 尤其在样本数和 ID 数都很大的情况下 (即样本很多, 但每一类对应的样本书目不太多) 非常适用. 关于 miamese networks 的更多信息可见 Signature Verification using a “Siamese” Time Delay Neural Network.
众所周知使用深度学习, 防止过拟合需要大量的数据. 但是早期的数据集如 VIPeR, iLIDS 等数据量都比较小 (几百张), 大部分使用深度学习的方法还是应用 mamese networks. Miamese networks 的缺点是不能充分利用标注信息. 后来提出了一些大规模的数据集比如 PRW 和 LSPS, 开始使用 classification networks 来进行 Re-ID.
除了 end to end 地提取特征, 当然也可以输入低层次特征来帮助生成高层次特征.
Video-based person re-id 数据集大小一般比 image-based 大很多, 因此更适用于使用深度神经网络来处理.
未来趋势
端到端系统
论文作者认为未来的 Person Re-ID 会是一个 end to end 的系统, 即把 detection 和 tracking 联合到一起作为一个整体, 输入 raw video/image. 当前大多数工作都假设前两步已经做好了, 而实际上当前使用的检测和跟踪系统并不完美, 势必对 Re-ID 的效果产生很大的影响, 必须在进行 Person Re-ID 时考虑到这种情况.
为此一些数据集被提出, 比如 CUHK03 和 Market-1501, 他们没有假设已经得到了很好地检测和跟踪结果.
超大规模 gallery 数据集
虽然几年来提出了一些规模较大数据集, 但和现实世界的数据规模相比还是小巫见大巫了. 举个例子, 当前数据集的数量级大概在 \( 10^4 \sim 10^5 \). 如果我们有 \(100\) 个摄像头, 采集速率为 \(1fps\), 平均每一帧能够产生 \(10\) 个 bounding box, 仅仅工作 \(12\) 个小时, 我们就会有 \(43.2\times10^6\) 的 bounding box! 可以说我们当前所拥有的方法对数据的消耗速度是远远小于数据的产生速度的, 所以要正在实现 Person Re-ID 的应用, 效率是必须考虑的问题. 在当前正确率还不算太高的情况下, 真是两头难顾.
当数据规模增大以后, 计算机的性能瓶颈也开始体现出来, 主要表现为需要的 I/O 时间大大增多, 甚至与真正的计算时间可比, 这将会严重限制数据的处理速度.
为了处理这个问题, 可以借鉴图像查询 (image retrieval) 的方法. 论文 [1] 中提供的两个方向是:
- 倒排索引 (inverted index-based)
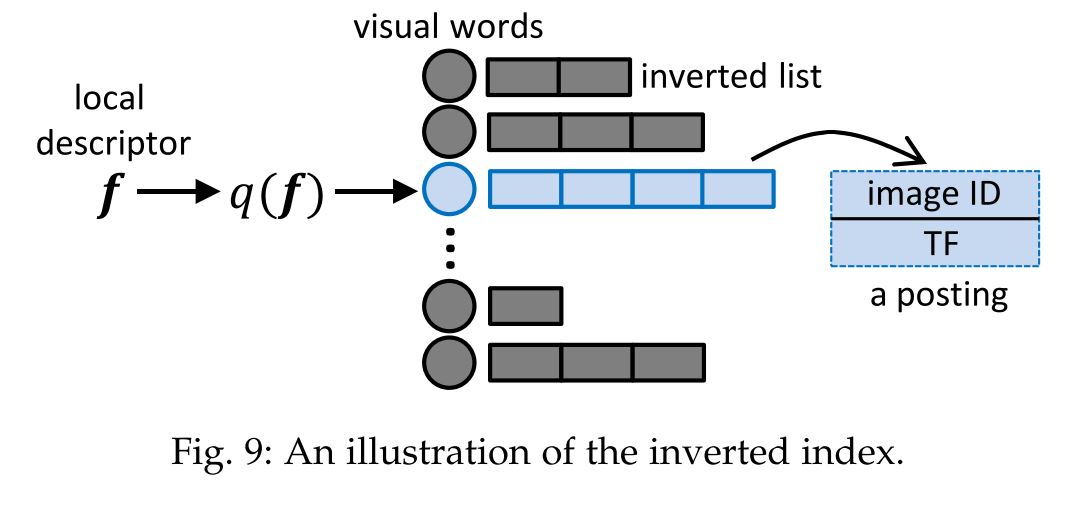
- 散列(Hashing)
散列方法在搜索最近邻中有广泛应用. 在图像查询方面, 散列函数是通过深度神经网络学习来得到的. 在这方面的工作还不多, 其中一个方法是使用带邻近连续性正则的 triplet-loss CNN 来学习散列函数, 见论文 Bit-Scalable Deep Hashing with Regularized Similarity Learning for Image Retrieval and Person Re-identification .