Features
- 99.619% 测试集正确率
- 可视化网络激活层的 feature map
- 拍照识别数字
所使用的技术
深度学习技术
- He Initializer, 即
\(f_{in}, f_{out}\)分别为输入, 输出神经元的个数.
- Residual Block
- Dropout
- Adam Optimizer
- Data Augmentation
- Model Emsemble 为了增强泛化能力, 一共训练了 3 个网络, 将 3 个模型的输出加到一起进行判断. 训练过程使用的算法是 AdaBoost.
- Capture Image Sharpening 使拍摄得到的图片拟合训练/测试数据集的分布
软件开发技术
- demo 程序界面: tkinter
所使用的的模型结构

Data-augmentation and Dropout
在训练过程中, 发现由于使用了比较深的网络, 导致了比较严重的过拟合, 因此考虑使用 Data-augmentation 和 Dropout 来增强泛化能力. 以下是这两种技术对训练过程和泛化性能的影响.
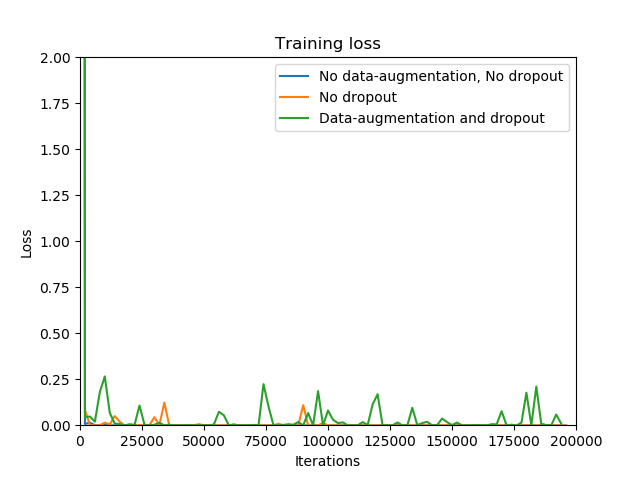
可以看到, 不使用 Data-augmentation 将会使 loss 迅速减少为 0, 明显过拟合, 此时几乎没有梯度下降. 而使用了 Data-augmentation 以后, loss 会产生震荡, 加入 Dropout 以后, 这种现象更加明显.
| Data-augmentation | Dropout | Training Set Accuracy | Test Set Accuracy |
|---|---|---|---|
| no | no | 1.0 | 0.991987 |
| yes | no | 0.997396 | 0.994691 |
| yes | yes | 0.997095 | 0.994591 |
Networks Boosting
训练过程中发现模型正确率一般在 0.9955 左右徘徊, 达不到所需要的 0.996, 或者只能偶尔达到 0.996, 因此使用 Boosting 方法, 训练 3 个网络进行判决. 使用的算法为 AdaBoosting. 使用 Boosting 以后每次训练结果都能达到 0.996.
Capture Image Sharpening
在训练完网络以后, 测试了模型的实际应用效果, 发现结果并不太好, 很多情况都会被识别为 8. 观察以后发现这是由于实际应用输入的图片和 Mnist 训练集和测试集的分布有较大的差别.


可以看到, Mnist 数据集的数据分布主要是在接近 0 和 255 间. 而我们通过摄像头拍摄的数据受限于光照条件等原因, 灰度往往集中在直方图的中间.
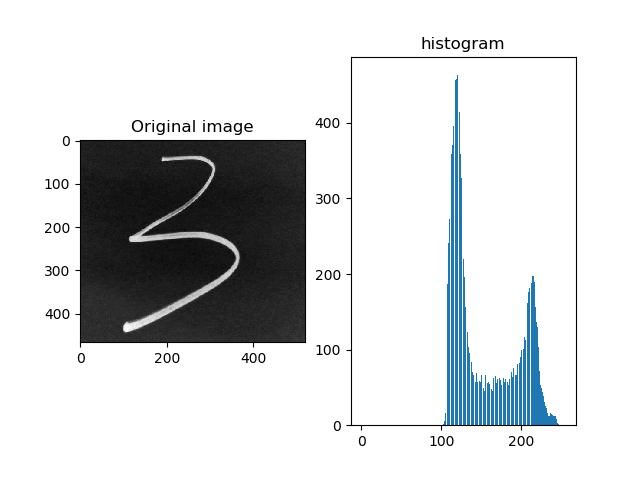
因此必须修正输入图像的直方图. 开始使用的方法是对图像进行伽马变换(当时数字图像处理课刚好上到图像灰度变换部分), 即
\[f(r)=cr^\gamma\]\(r\) 为输入像素, \(\gamma\) 为 3.0 ~ 7.0 之间的常数. 进过该变换以后得到
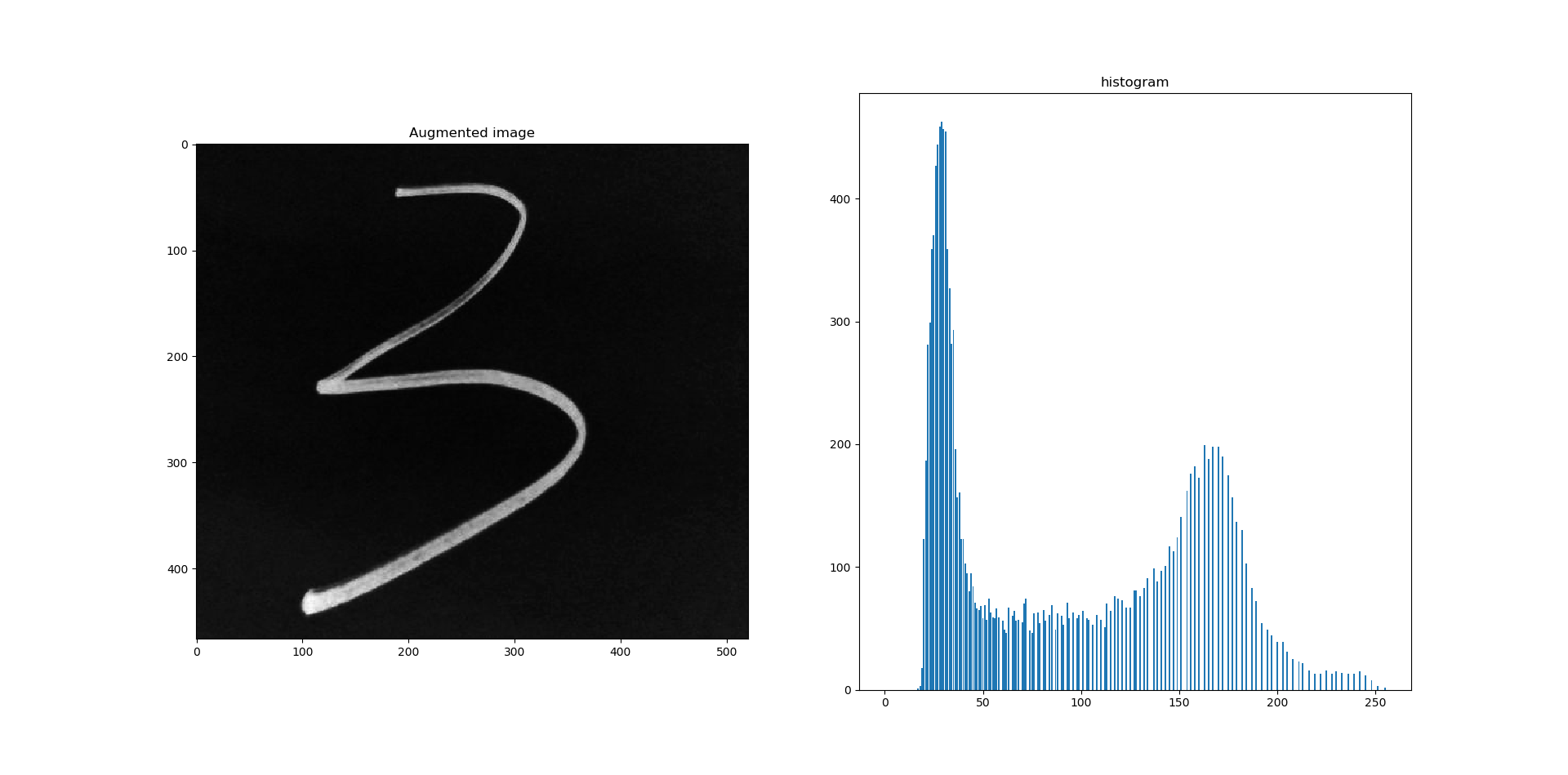
这样与测试数据集分布更为接近一些, 测试结果也大为改观. 之后数字图像处理课程又学习了直方图规定化处理, 因此之后可以考虑使用这种方法进一步拟合测试数据集.
Demo
主界面
开启摄像头, 可以进行拍照并截取数字
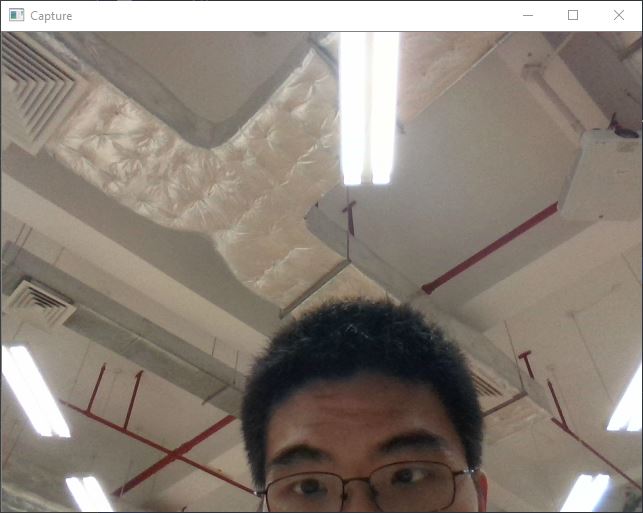
选择一张图片, 并进行测试

可以看到, 测试结果正确. 本人尝试了一些手写体和印刷体数字, 都能够识别正确.
可视化 feature map
直接将每一个 feature map显示出来结果如下所示




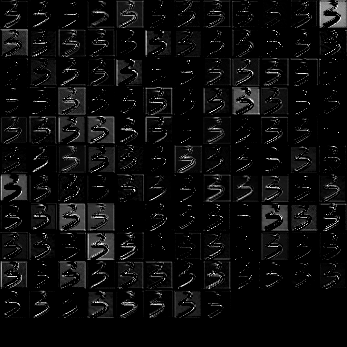
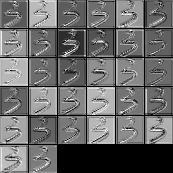
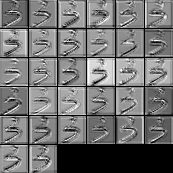
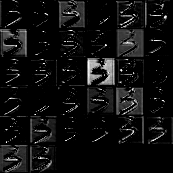




另一种可视化技术使用论文 Visualize and Understanding Convolutional Neural Networks 中的方法, 即对每一个 feature map 进行(反)激活, unpooling 和 deconvolution. GitHub 上已经有一个比较完善的实现[4], 因此配置以后直接调用即可. 结果如下所示:





分析
网络的确能够提取到图像不同的特征, 但由于 Mnist 数据集分布比较单一, 特征也不太多, 并不需要用太深的网络来处理. 可以看到, feature map 中有很大部分都有非常相似的结果. 使用太深的网络还带来严重的过拟合问题, 如前所述, 必须采样强有力的抗过拟合方法才能改善泛化性能. 因此之后尝试训练了一个比较浅的网络, 正确率为 0.9961939102564102. 网络结构如下

结果:
| Model | Training Set Accuracy | Test Set Accuracy |
|---|---|---|
| 1 | 0.997095 | 0.99369 |
| 2 | 0.9999 | 0.98758 |
| 3 | 1 | 0.992188 |
| Emsembled | 0.9961939102564102 |
可以看到, 模型性能与深层网络基本相同, 甚至更优. 证明之前的推断正确.
其他讨论
- 实验中比较了 SGD 优化算法和 Adam 优化算法的收敛速度, 发现 Adam 的收敛速度确实快很多, 且震荡现象不明显.
- 实验中还尝试了使用 BatchNorm, 但提升并不大. 猜测是由于 BatchNorm 主要用于提高收敛速度, 而实际收敛速度已经非常快了(大约 30k loss 就能达到一个很低的水平), 因此加入了 BatchNorm 反而降低了模型的性能.
感想
Mnist 的分类之前虽然尝试过, 但并没有对正确率有太高的要求, 且初次接触, 没有进行太深入的探究. 本次任务要求 0.996 的正确率, 虽然对于深度学习来说拟合 Mnist 数据集并不是一件太难的事情, 但要达到很高的正确率还是需要比较认真考量模型结构, 调整参数. 本次任务过程中我也尽量尝试了之前论文, 博客上看到的技术, 比如 Dropout, BatchNorm, Feature map 可视化技术等等. 所以说这次体验收获还是非常大的.
参考文献
- Visualize and Understanding Convolutional Neural Networks
- 李航. 统计学习方法
- Feature Visualizing
- https://github.com/InFoCusp/tf_cnnvis/
- https://distill.pub/2017/feature-visualization/
- http://link.springer.com/10.1007/978-3-319-10590-1_53%5Cnhttp://arxiv.org/abs/1311.2901%5Cnpapers3://publication/uuid/44feb4b1-873a-4443-8baa-1730ecd16291